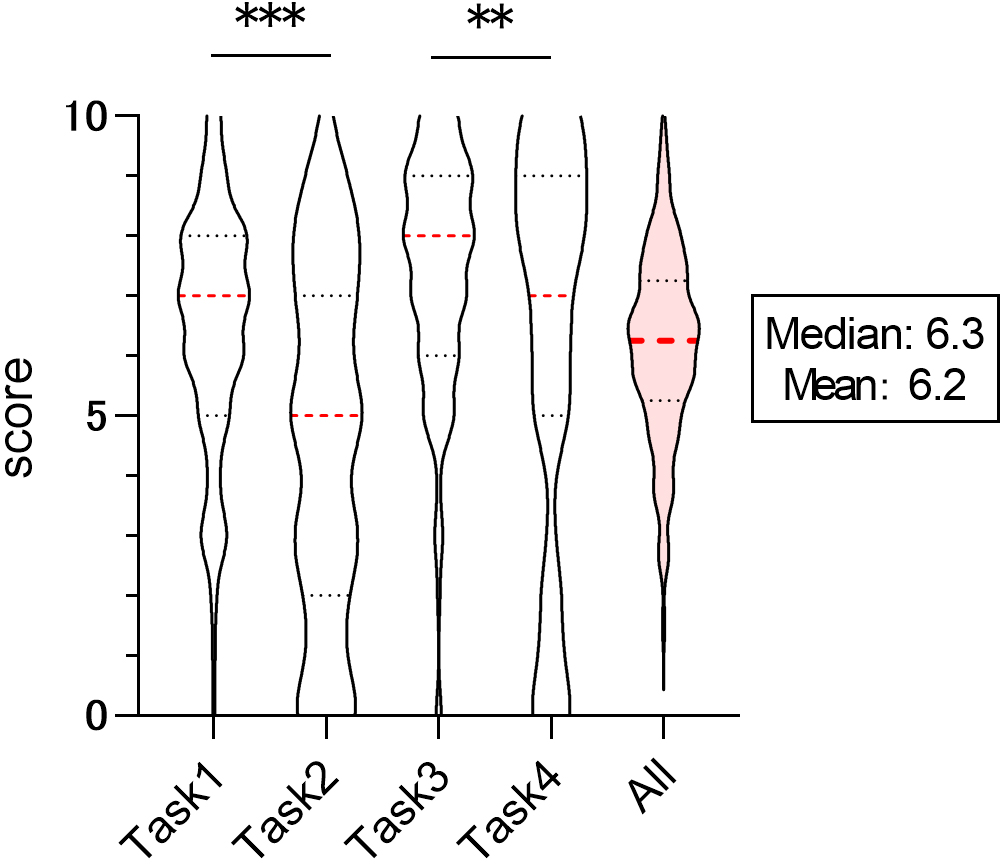
Figure 1. Evaluation of ChatGPT’s responses to medical assignments by medical students. A violin plot illustrates the results of scoring ChatGPT’s performance on each of the four individual tasks and the overall assignments, rated on a 10-point scale. **p < 0.01, ***p < 0.001 determined by Wilcoxon’s signed rank test.